
Understanding User Intent Through AI Bot Traffic: A Practical Framework
Turning Bot Logs into Actionable Insights for Product & SEO Teams


This article is also available as a podcast! If you’re on the go or just want to absorb the content in audio format, you can listen to the full episode below 👇 The podcast is also available on Spotify and Apple Podcasts.

A growing blind spot is emerging in website analytics: the user intent behind AI assistant traffic.
Every day, ChatGPT, Claude, Perplexity, and other AI tools visit documentation, scan product pages, and access content on behalf of real users searching for answers. While modern analytics platforms have sophisticated bot filtering mechanisms that automatically exclude spam bots and malicious crawlers [1], they face a different challenge with AI assistants: these tools represent genuine user needs, yet their traffic patterns are fundamentally different from direct human browsing.
The problem isn’t simply about filtering, it’s about context loss. When a user asks an AI assistant “How do I integrate payment processing with [product X]?” or prompts it to “Compare pricing plans for [service Y],” the resulting bot traffic to those websites represents authentic user intent. And with assistants increasingly grounding their answers in real-time web search and retrieval, not just relying on their pre-trained LLM weights, these visits are happening continuously, invisibly, and with growing frequency.
Moreover, most users receive the final answer directly inside the AI interface without ever clicking through to the original site [2]. This creates an “invisible visit” phenomenon where content provides value, AI systems access and process the information, but traditional analytics either record nothing or strip away the critical context of what the user was actually trying to accomplish.
Recent research suggests AI crawler traffic accounts for 5-10% of total server requests for knowledge-based websites [2], yet this traffic is either aggregated into generic “bot” categories or excluded entirely. The distinction matters: newer AI crawlers often aren’t covered by standard bot filtering lists [3], and even when detected, analytical frameworks treat them like search engine crawlers rather than proxies for human questions and needs.
Objective
This article presents a practical framework for extracting actionable intelligence from AI bot traffic, treating it not as noise to filter out, but as a complementary signal that reveals user intent.
After reading this article, you will understand:
Why does AI bot traffic contain different intelligence than traditional analytics? How AI-mediated user interactions fundamentally differ from direct human browsing, what makes them valuable despite being non-human traffic, and why current analytics frameworks fail to capture this value
What insights can be extracted from AI bot access patterns? Which specific patterns in bot traffic reveal user questions, documentation gaps, and product understanding issues, supported by analysis of real-world data
How can organizations operationalize AI bot insights? Practical methods to segment, analyze, and integrate AI bot data into product, content, and marketing workflows, with concrete examples from actual implementation
Whether you’re a product manager trying to understand user needs, a data analyst seeking new signal sources, or a content strategist optimizing documentation, this framework will help you see AI bot traffic not as a measurement problem, but as an untapped source of user intelligence.
This article is part of a series exploring the evolving landscape of AI-powered search and content discovery, available at https://siteline.ai/blog/. SiteLine is a platform that tracks and optimizes product and service visibility across the AI search ecosystem, providing comprehensive insights into how brands perform in AI-powered responses from ChatGPT, Perplexity, Gemini, Claude, and other AI assistants.
Prerequisites: No prior knowledge is required. The concepts are explained in and accessible way for anyone interested in how AI assistant traffic can inform business and content strategy.
1. The Framework in Brief
The Core Innovation: Why LLMs Beat Clustering
Most teams try to understand user behavior with URL rules, regex, or embedding-based clustering. The problem: these methods are descriptive, not interpretive. They group hits that look similar on the surface, but they can’t reconstruct the story behind a session.
For instance, basic clustering might lump together a “Pricing” page visit and a “Login” attempt simply because they share common keywords or happened in sequence. This means you can’t distinguish between a new prospect moving through your sales funnel and an existing customer performing routine tasks. The critical difference between someone evaluating your product versus someone already using it is completely invisible in your analytics.
This framework flips the approach:
Instead of pre-defined rules, we use an LLM as a reasoning engine.
Instead of isolated pageviews, we analyze full journeys: which pages were visited, in what order, and for how long.
Instead of a fixed taxonomy, we let the model create dynamic tags and categories as it discovers new patterns in the traffic.
Instead of generic tags, we ask the model to interpret the session: who is behind this query, and what are they trying to do?
In other words, we move from “this session visited /pricing and /docs” to “this is a developer evaluating integration feasibility based on API limits, then checking whether the pricing fits their use case.”
How It Works: The 4-Stage Process
The framework treats every AI bot visit as a breadcrumb trail, reconstructing them into coherent sessions to decode the human intent behind the prompt.
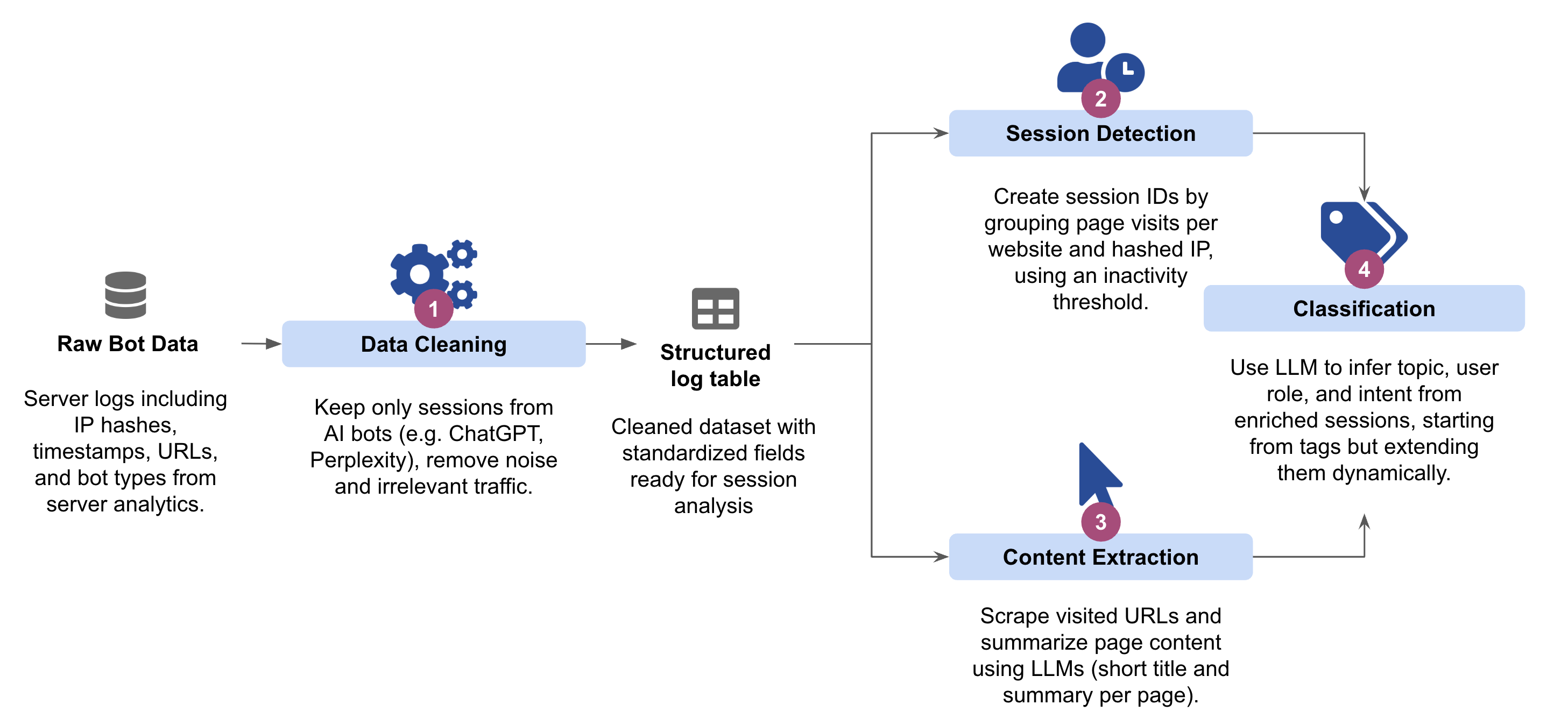
Stage 1: Separating Signal from Noise The analysis starts at the source: server logs. Unlike traditional web analytics that rely on JavaScript tracking pixels and client-side sessions, AI assistant visits leave traces in the raw HTTP request logs maintained by your hosting infrastructure, whether that’s an edge service like Vercel, a CDN like Cloudflare, or your origin servers.
A typical log entry might look like this:
185.72.144.53 yourwebsite.com - [12/Feb/2025:14:32:09 +0000]
"GET /features/our-brand-new-awesome-feature HTTP/1.0" 200 64312 "-"
"Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/97.0.4692.71 Mobile Safari/537.36
(compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
Raw data is filtered to keep only AI assistants acting on real user queries, removing noise from SEO crawlers, uptime monitors, spam bots, and internal automation.
Stage 2: Reconstructing User Journeys > Individual hits are grouped by IP address and temporal proximity. A natural break in activity (e.g., a 5-minute gap) signals the start of a new session. This transforms your bot logs from a list of disconnected URLs into a collection of browsing narratives, each representing someone’s attempt to understand something about your product or service.
Stage 3: Semantic Enrichment > To decode cryptic URLs, the system scrapes every unique page visited and uses a lightweight LLM to generate a semantic title and summary. This translates technical paths (e.g., /docs/v2/auth) into a clear sequence of consumed concepts, creating a human-readable storyline for the LLM to analyze.
Stage 4: Inferring User Intent > A reasoning LLM analyzes the full enriched journey to answer three core questions, assigning a confidence score to each classification:
Topic: What is the precise subject? (e.g., “Payment Integration Errors”).
Role: Who is the user? (e.g., Developer vs. Decision-Maker).
Goal: What are they trying to do? (e.g., Evaluation vs. Active Implementation).
This final stage converts raw data into dynamic, quantified insights that evolve automatically as new content and user behaviors emerge.
2. Case Study: What the Data Actually Reveals
Let’s see what happens when the framework is applied in practice. For this analysis, server logs were collected from three pilot websites over a 24-hour period and filtered to isolate only ChatGPT bot traffic. For this analysis, we’ll go in depth with Tradevision.io, a data platform for stock and options trading.
Anatomy of an AI-Mediated Session
Before examining aggregate patterns across thousands of sessions, let’s trace a single journey to understand what session reconstruction and LLM-based classification reveals and why it matters.
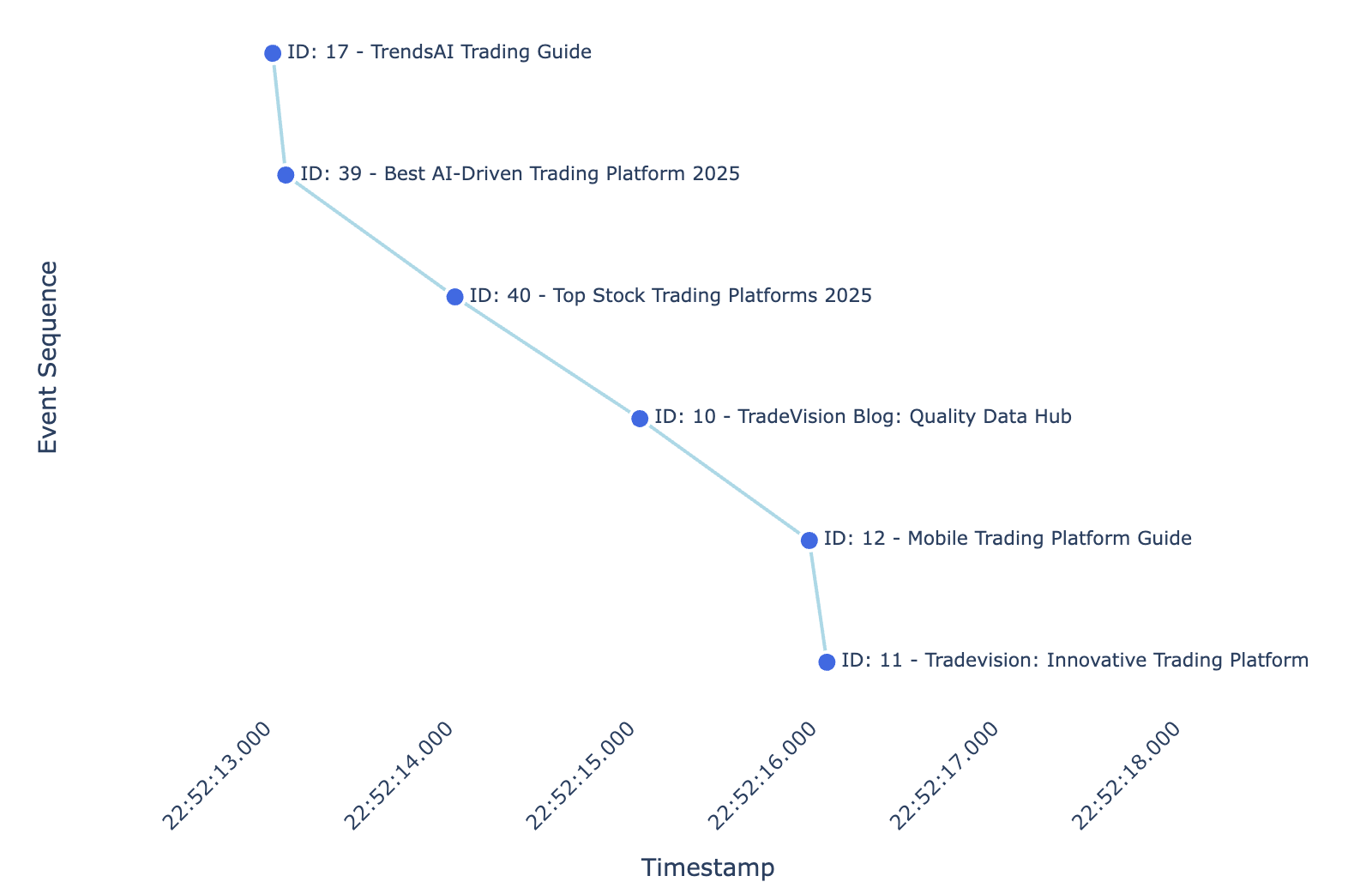
The framework’s LLM classifier analyzed this sequence and produced:
- Topic: Trading platform review
- User Role:decision-maker(confidence: 90/100)
- Intent Type:comparison(confidence: 92/100)
- Reasoning: The session comprises multiple TradeVision blog pages focused on comparing and evaluating trading platforms (AI-driven tools, 2025 platform rankings, mobile vs desktop, and platform reviews). This indicates a decision-making, comparison-oriented intent rather than learning or implementation.
This session likely reflects a user asking something like “What’s the best AI trading platform for mobile in 2025?” The assistant gathered comparative information step by step, moving from general guidance to specific recommendations to product details.
The next sections scale this analysis across thousands of sessions to reveal broader patterns in user segmentation, content performance, and optimization priorities.
Topic Distribution: Identifying Content Opportunities
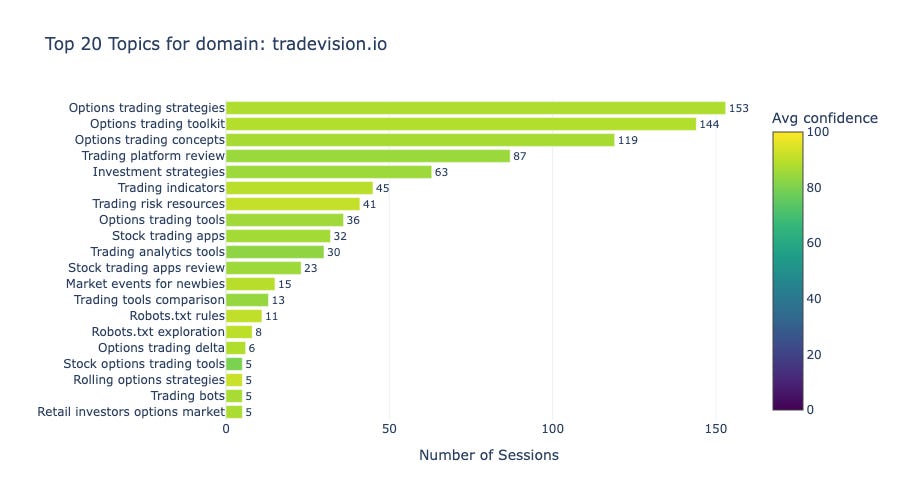
The traffic data reveals two dominant themes: strong demand for options trading education and consistent interest in platform comparison content. Understanding these patterns helps identify where content investment delivers the highest return for tradevision.io in AI search visibility.
Figure 3 shows that options trading content captures over 400 sessions across three related topics: “Options trading strategies” (153), “Options trading toolkit” (144), and “Options trading concepts” (119). Together, these three topics account for 47% of all sessions, out of a total of 873.
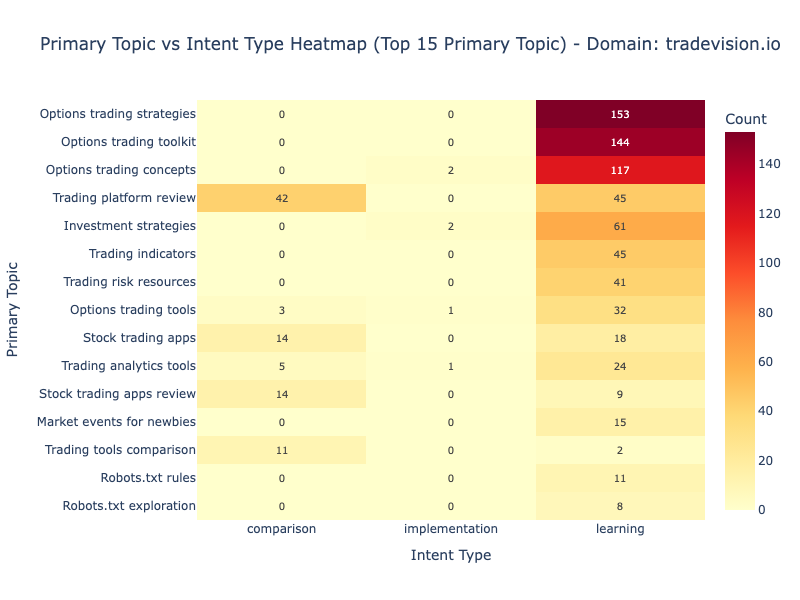
The topic-intent relationship displayed in Figure 4 shows distinct patterns. Options content attracts pure learning intent while “Trading platform review” shows balanced distribution, indicating the content successfully serves both discovery and evaluation stages.
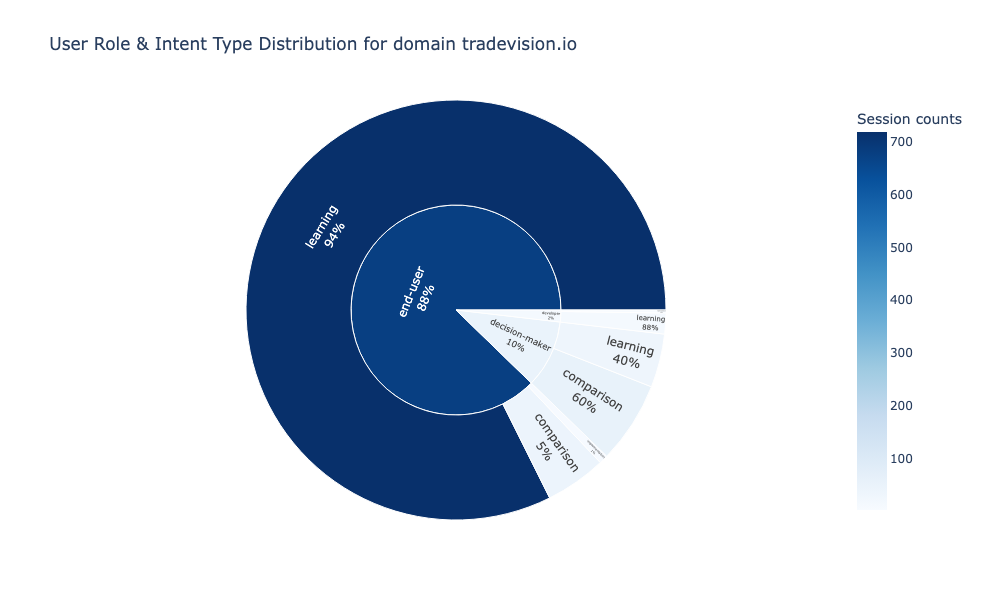
User Segmentation: Understanding User Roles, Intent, and Behavioral Patterns
The findings become even stronger when we analyze the user-level segmentation.
Figure [8] shows that end-users represent the majority of traffic and demonstrate 93.9% learning intent with minimal comparison (5.4%). Decision-makers show the inverse pattern: 60.4% comparison intent with secondary learning (39.6%).
These fundamentally different browsing behaviors reflect different stages in the consideration journey, end-users building knowledge, decision-makers actively evaluating alternatives.
3. Why This Matters: Strategic Implications
The Zero-Click Blind Spot
For Tradevision, AI assistants account for 17% of all sessions to content about options trading strategies. Traditional analytics, however, register zero visits, zero engagement, zero value. And yet, real users received answers, while AI systems began associating TradeVision with expertise in options trading.
This is the core challenge: content is delivering business value without activating conventional success metrics. Companies focused only on direct traffic are measuring a shrinking slice of how users actually discover, evaluate, and understand their products. This framework surfaces that hidden demand.
Early Signal Detection as Competitive Edge
AI assistants capture user intent long before a prospect commits to visiting a website, trying a product, or contacting support.
Consider the case of TradeVision. By analyzing AI search behavior, they detected a surge of decision-makers on platform comparison pages but there was near-zero intent to actually implement the software. Traditional funnel analysis would simply see this as “bounced traffic,” but AI signals revealed a potential issue: a hidden onboarding gap?
This kind of signal allows for a predictive strategy:
Fix friction before it escalates into support tickets.
Expand content before feature requests pile up.
Claim ownership of topics before competitors even notice the trend.
The Compound Effect: Most importantly, this first-mover advantage compounds over time. When AI assistants consistently cite TradeVision for options trading, they build deep mental associations. Competitors entering the market later face a steeper challenge: they must not only match the product but also unseat an established algorithmic bias in your favor.
AI Discoverability: The New Game
While traditional SEO focuses on visibility on a search engine results page, AI discoverability focuses on retrieval and citation. The goal is to be the primary source used by an assistant to generate an answer, often without the user ever visiting a website.
This shift demands that we prioritize structure over keywords.
TradeVision exemplifies this success. Their content performs well not due to backlink volume, but because it is architected for synthesis as it provides self-contained, comprehensive answers. Conversely, content strategies that fragment information across multiple pages perform poorly in AI-mediated discovery.
The proposed framework allows companies to audit their digital footprint, identifying which assets successfully serve this new discovery layer and which are invisible to the algorithms that matter most.
What’s Next?
AI assistant traffic represents a paradigm shift in how we understand user behavior online. Traditional analytics tell us what users do when they visit our sites, which pages they view, how long they stay, and where they click. AI bot traffic, when properly analyzed, reveals something more fundamental: what users are trying to accomplish before they even decide whether to visit.
These insights can be operationalized across teams.
Product managers can spot recurring workarounds or friction points that assistants repeatedly access and prioritize features accordingly.
Content teams can identify high-traffic topics where assistants still struggle to find clear answers, signaling documentation gaps.
Marketing and sales can understand the comparison patterns and evaluation criteria users rely on long before they land on the pricing page.
Engineering teams can uncover technical blockers such as rate limits, authentication quirks, crawler-unfriendly endpoints [1] [5].
There are limitations. Session attribution remains imprecise, as a single user query can trigger multiple bot requests across different pages. Intent inference has natural boundaries: sequences reveal likely goals, but without the original prompt, certainty is impossible. And AI behavior itself evolves as models and retrieval systems improve, requiring the framework to adapt continuously.
References
[1] Google Analytics Help. “[GA4] Known bot-traffic exclusion.”
[2] Writesonic. (2025). “Introducing AI Traffic Analytics: Track Traffic from ChatGPT, Gemini & Perplexity.”
[3] IronPlane. (2025). “How to Clean Up Your Google Analytics Data from AI Bot Traffic.“
[4] Vlad Zotov, The AI Crawler Optimization Guide to Increase Site Visibility, Siteline
[5] Giacomo Zecchini, Alice Alexandra Moore, Malte Ubl, Ryan Siddle, The rise of the AI crawler, Vercel