
SkillOpt Explained: From Prompt Engineering to Skill Training
A Deep Dive Into SkillOpt’s Framework, Experimental Results, and Open-Source Implementation.


This article is also available as a podcast! If you’re on the go or just want to absorb the content in audio format, you can listen to the full episode below 👇 The podcast is also available on Spotify and Apple Podcasts.

Skills are quickly becoming a standard way to build AI agents, packaging expertise and workflows into reusable instructions. Claude Skills helped popularize the idea, and today most agent frameworks rely on some form of skill-based architecture.
But there’s still no real science to building them. Most teams rely on a cycle of writing, testing, and rewriting instructions until they get acceptable results.
SkillOpt takes a different approach. Instead of treating a skill as fixed text, it treats it as something that can be improved through evaluation and feedback, more like training a deep learning model than prompt engineering.
Objective
This article explores how SkillOpt applies the principles of model training to natural-language skills, what its experiments reveal, and where the approach reaches its limits.
By the end, you’ll understand:
How SkillOpt works: why skills can be treated as trainable state, how the four-phase optimization loop operates, and which parameters influence the outcome.
What the experiments show: the benchmarks, evaluation methodology, performance gains, and failure modes.
How to use SkillOpt in practice: setting up the open-source library, optimizing a skill on your own dataset, and comparing agent performance with and without skill optimization.
Prerequisites: A basic understanding of LLMs, prompt engineering, and machine learning training concepts is helpful, but not required.
Tools & libraries: SkillOpt, the SearchQA dataset, and an LLM backend (Azure OpenAI, OpenAI, Anthropic, or a local Qwen).
1. Inside SkillOpt: How It Works
The core idea behind SkillOpt is that skills can be optimized using principles similar to those used for neural network training.
1.1 What is a skill, and why do manually designed skills plateau?
A skill is a compact instruction document that guides a frozen agent. It specifies how the agent should gather evidence, use tools, verify results, and structure its final answer. The model weights remain fixed, and the execution harness remains unchanged. Only the skill text evolves from one run to the next. For a more detailed discussion of skills and their role in agent systems, see my previous article, *Building Claude Skills: A New Paradigm for Interacting with LLMs.*
Today, most skills are created in one of three ways, and all three approaches eventually plateau.
Manually designed skills: whether authored by humans, generated by an LLM, or refined through iterative prompting. They depend heavily on prior intuition.
One-shot generated skills: They are produced by an LLM in a single pass, without feedback from actual task outcomes. Although they often appear well-structured and comprehensive, they are not grounded in observed performance.
Self-revising skills: They allow an agent to rewrite its own instructions after each episode. However, without systematic evaluation, useful rules can be replaced by weaker alternatives, causing the skill to drift rather than improve.
The common limitation is the absence of optimization discipline. Deep learning addressed a similar challenge through controlled updates, validation, and systematic use of failure signals. SkillOpt introduces the same principles into skill optimization. Instead of updating hidden parameters, it updates instructions. Instead of gradients, it relies on evidence collected from real executions. The result is a training process for skills that is measurable, reproducible, and auditable.
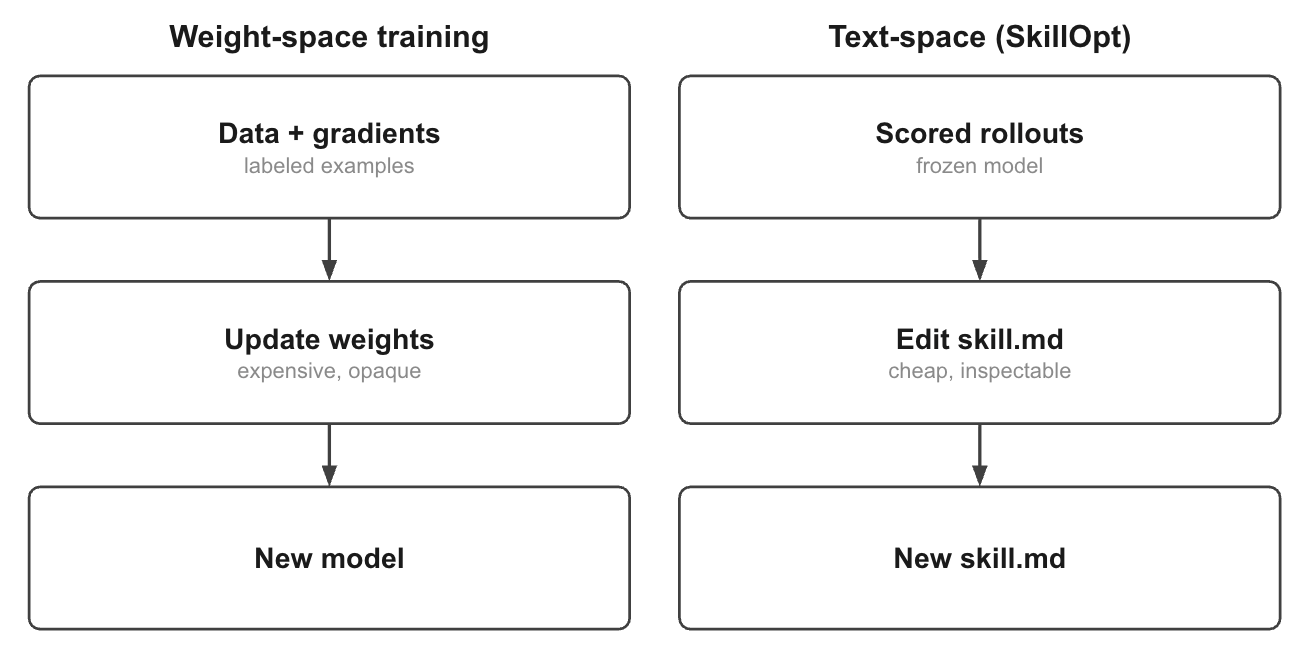
1.2 What happens during one training step?
A single SkillOpt iteration follows the same pattern as any optimization loop: observe behavior, identify what went wrong, propose an improvement, and test whether it actually helps. To make the process concrete, consider a SearchQA example:
Which 1851 novel features the whaling ship Pequod?
with the gold answer:
Moby-Dick
By the end of the iteration, the skill may have gained a new instruction, or remained unchanged. The outcome depends entirely on whether the proposed edit improves performance on unseen examples.
#1. Rollout: collecting behavior
The process begins with a rollout. Using the current skill, the frozen target model answers a batch of questions while SkillOpt records its behavior. Each trajectory contains the prompt, the model’s responses, any tool interactions, and the final answer. A verifier then scores the result.
For example, the model might answer:
The novel is Moby-Dick by Herman Melville.
Although factually correct, the response receives a score of zero under exact-match evaluation because the expected answer is simply Moby-Dick. The rollout therefore captures a failure despite the model possessing the relevant knowledge.
#2. Reflection: identifying patterns
A separate optimizer model reviews both successful and unsuccessful examples. Rather than inspecting model parameters, it analyzes behavior. By comparing failures against successes, it can distinguish recurring weaknesses from instructions that are already working well.
In this case, the optimizer notices that many incorrect examples contain the right answer wrapped in unnecessary explanation, while successful examples tend to return concise answer spans. That contrast becomes the learning signal.
Reflection plays a role analogous to a backward pass: it converts observed outcomes into a direction for improvement.
#3. Edit: proposing a change
Once a pattern has been identified, SkillOpt translates it into a concrete modification of the skill.
The system operates through three simple edit operations:
Add a sentence
Remove a sentence
Replace a sentence
For the running example, the optimizer might propose:
Answer using the shortest exact span without additional explanation.
Several candidate edits are usually generated. They are merged, ranked, and filtered through an edit budget that limits how much the skill can change in a single iteration.
At this point, the edit is only a hypothesis.
#4. Validation: earning a place in the skill
Before becoming part of the skill, the proposed change must prove its value.
SkillOpt evaluates the candidate skill on a held-out validation split that was never used during reflection. This prevents the system from optimizing for quirks in the current batch and mirrors the role of validation sets in supervised learning.
With the new instruction, the model now answers:
Moby-Dick
If validation performance improves, the edit is accepted and incorporated into the skill. If performance stays flat or declines, the edit is discarded and the previous skill is retained.
This validation gate is what gives SkillOpt its optimizer discipline. A sentence enters the skill only after demonstrating measurable benefit.
One complete pass through the training set constitutes an epoch. Across batches and epochs, the rollout–reflection–edit–validation cycle repeats, gradually refining the skill through a sequence of validated improvements.
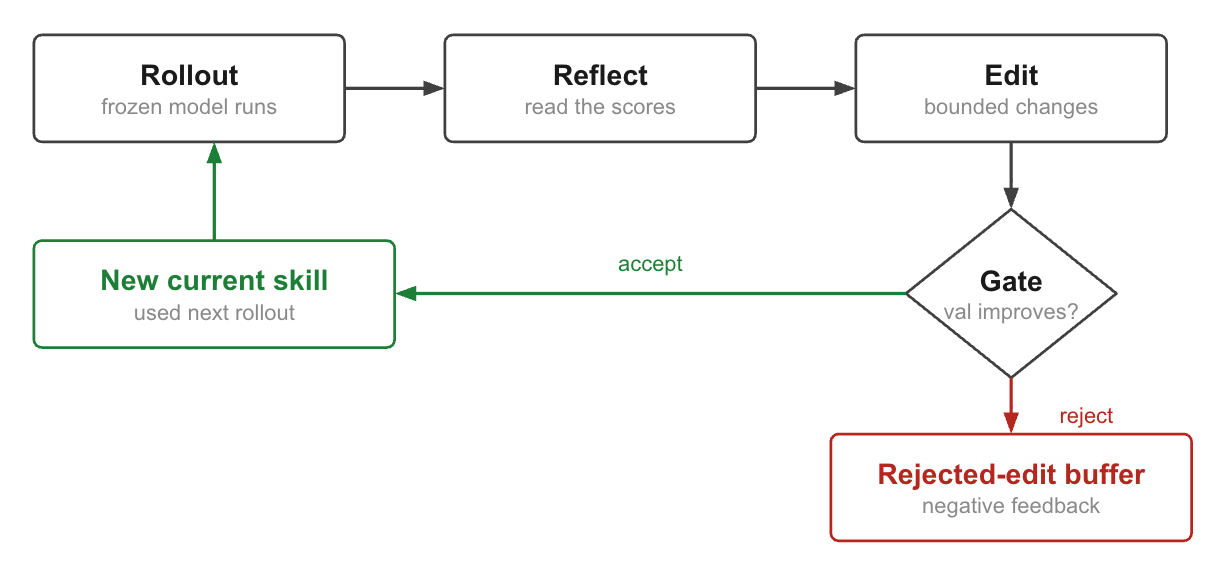
1.3 What keeps the optimization loop stable?
SkillOpt avoids uncontrolled self-modification through four mechanisms that mirror the safeguards used in traditional machine learning optimizers.
1. Bounded updates: the textual learning rate
In neural network training, the learning rate controls how far the optimizer can move the weights in a single update. SkillOpt applies the same idea to text through an edit budget, sometimes described as a textual learning rate.
The budget limits how many add, delete, and replace operations can be applied during one optimization step.
The default budget is four edit operations per step. In the paper’s ablation study, removing this constraint reduces SearchQA performance from 87.1 to 84.6.
2. Validation: every edit must earn its place
A reflection is only a hypothesis. Before becoming part of the skill, an edit must prove that it improves performance.
SkillOpt evaluates every candidate skill on a held-out validation split that was never used during reflection. This prevents the optimizer from overfitting to the examples that inspired the edit.
By default, SkillOpt uses a hard gate based on exact-match accuracy. A candidate is accepted only if it scores higher than the current skill. For smaller validation sets, the repository also provides a soft gate that uses partial-credit metrics such as token overlap.
3. Memory: learning from past mistakes
Unlike a simple self-revision loop, SkillOpt remembers what happened in previous optimization steps.
It does this through two mechanisms:
Rejected-edit buffer: Rejected candidates are not discarded. Instead, they are stored as negative examples and shown to the optimizer during future reflections. This reduces repeated mistakes and discourages previously unsuccessful edit directions. Removing the buffer reduces SearchQA performance from 87.1 to 85.5.
Slow update: Individual batches are noisy. A good edit may fail validation simply because of batch variation. The slow-update mechanism periodically revisits the skill from a broader perspective. This smooths out noisy updates, captures improvements missed by individual batches and helps training recover from local mistakes.
4. Meta skill: improving the optimizer itself
SkillOpt maintains a second document called the meta skill.
The distinction is important:
Skill → instructions used by the target model to solve tasks.
Meta skill → instructions used by the optimizer model to improve the skill.
Think of the skill as the player’s playbook and the meta-skill as the coach’s notebook. The player follows the plays, but the coach keeps notes on what wins games, what mistakes keep showing up, and which tactics are unlikely to succeed. The notebook guides future decisions even though the player never sees it.
Benefits:
Accumulates optimization knowledge over time.
Improves the quality of future edits.
Does not increase inference-time cost.
The paper reports the largest performance drop when both the meta skill and slow-update mechanism are removed, with SpreadsheetBench falling from 77.5 to 55.0.
2. Key Findings from the Experiments
To evaluate that question, the authors tested SkillOpt across a diverse set of tasks, models, and agent frameworks.
2.1 How was SkillOpt evaluated?
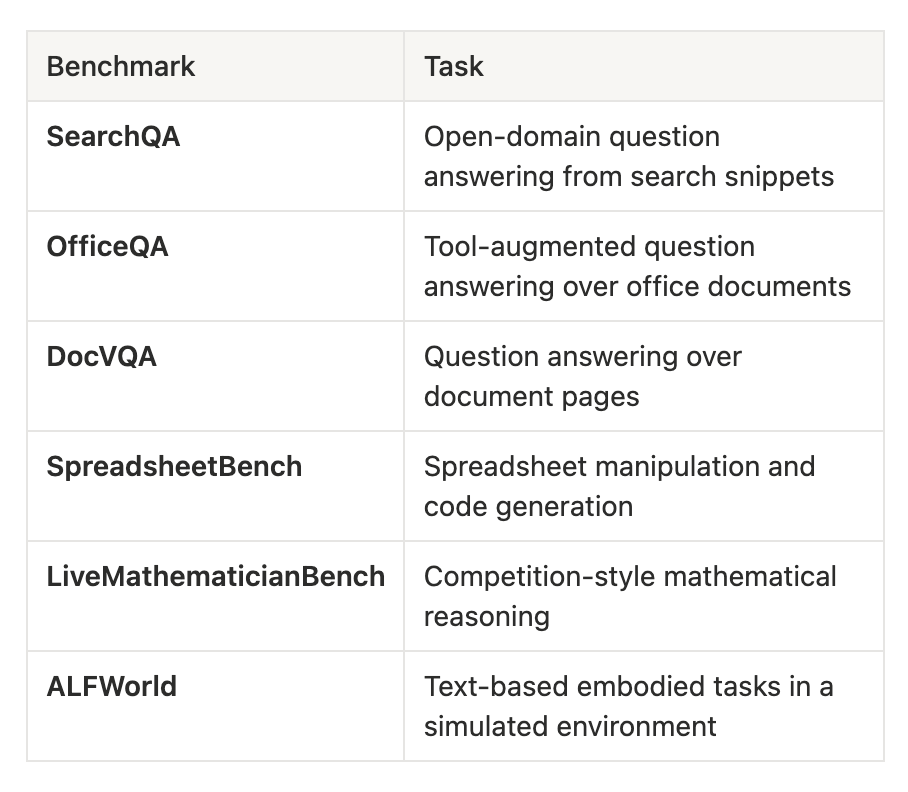
The evaluation spans six benchmarks covering different types of agent behavior:
The experiments use seven target models, ranging from smaller GPT variants to frontier models and open-source Qwen models. The target model is the agent being adapted. A separate optimizer model proposes edits to the skill. In the paper’s primary configuration, GPT-5.5 serves as the optimizer while the target model varies across experiments.
SkillOpt is compared against several classes of baselines:
No skill: the model runs without additional instructions.
Static skills: manually designed or one-shot LLM-generated skills.
Prompt optimizers: methods such as TextGrad and GEPA that improve prompts from trajectory feedback.
Skill-evolution methods: approaches like Trace2Skill and EvoSkill that rewrite the skill over repeated runs, learning from what the agent did and whether it worked.
2.2 How are the results scored?
Each benchmark defines its own notion of success, but the reporting follows the same pattern.
Every task receives a score from a benchmark-specific verifier:
SearchQA uses exact-match accuracy.
OfficeQA and DocVQA compare answers against reference outputs.
LiveMathematicianBench verifies the final mathematical answer.
SpreadsheetBench evaluates whether the produced spreadsheet satisfies the target specification.
ALFWorld measures task completion.
Scores are normalized between 0 and 1 and then averaged across the evaluation split. The final benchmark score is reported as a percentage.
One detail is important when reading the paper’s tables: most headline results are reported as gains, not absolute scores. +9.6 means SkillOpt improved accuracy by 9.6 percentage points relative to the same model without a skill.
2.3 What were the headline results?
The headline result is straightforward: SkillOpt consistently outperformed every baseline. Across all 52 evaluation settings, spanning different models, benchmarks, and execution environments (Claude code or codex), it was either the best or tied for the best-performing method.
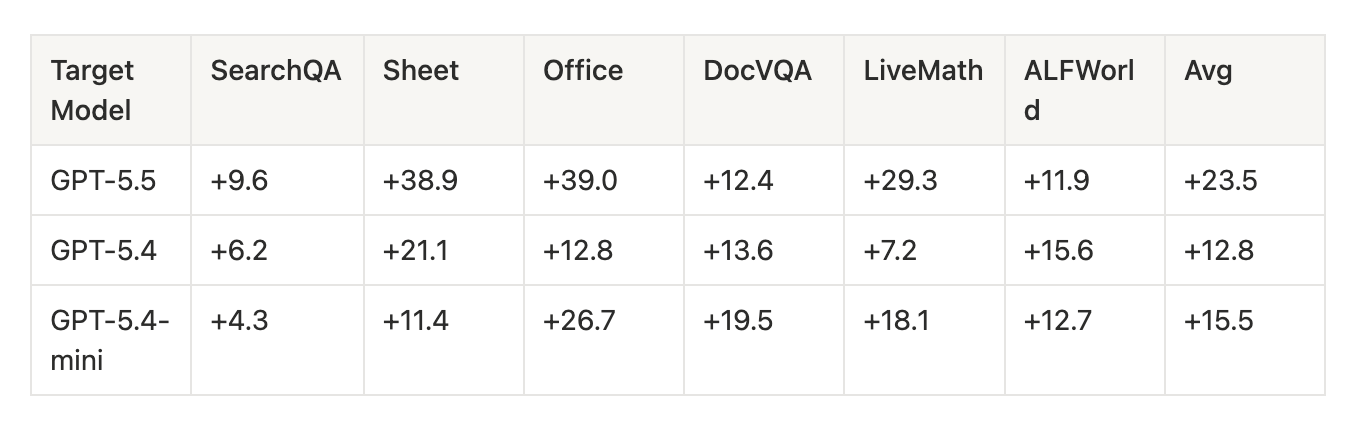
On GPT-5.5, the optimized skills improved average accuracy by 23.5 percentage points over the no-skill baseline.
A clear pattern emerges from the table.
**The largest gains appear on procedural tasks (**SpreadsheetBench: +38.9, OfficeQA: +39.0, LiveMathematicianBench: +29.3). These tasks benefit from explicit procedures, verification steps, and tool-usage rules—the exact kinds of behavior encoded in a skill.
Knowledge-heavy QA tasks improve less, but still improve. SearchQA: +9.6, DocVQA: +12.4 When a model already knows the answer, a skill has less room to help. It can improve formatting, retrieval strategy, and verification, but it cannot add knowledge that is not already present in the model.
The same trend appears across smaller models: The exact gains vary, but the overall conclusion remains the same: skills help both frontier models and smaller models.
Two additional findings are particularly relevant for practitioners.
Skills transfer: The optimized skills are not tightly coupled to the model or environment they were trained on. The paper reports successful transfer across: different model sizes, different execution harnesses, related benchmarks within the same domain.
Skills remain small: The final artifact is surprisingly lightweight. Typical optimized skills contain roughly 300–2,000 tokens and are often produced after only one to four accepted edits. The resulting instructions are also easy to inspect. Rather than discovering obscure prompt tricks, SkillOpt tends to learn straightforward operational rules.
2.4 Where does the approach break?
The method is powerful, but it has clear limits.
Bounded by the target model. The skill can improve how the model works, but not what the model fundamentally knows or can do.
Dependent on optimizer quality. Stronger optimizers tend to discover better edits, while weaker ones generate more proposals that fail validation.
Compute-intensive. Training requires repeated rollouts, reflection, and validation, making optimization significantly more expensive than writing a skill once.
Sensitive to validation quality. The gate is only as reliable as the held-out split. Small validation sets can make useful improvements difficult to detect.
Task-dependent gains. The largest improvements appear on structured, procedural tasks such as spreadsheets and office workflows, while open-ended QA generally sees smaller gains.
In practice, SkillOpt works best when the target model already has the underlying capability, the validation split is large enough to provide reliable feedback, and the task rewards consistent procedures rather than broad world knowledge.
3. Applying SkillOpt in Practice
The headline results in the paper are impressive, but the more practical question is: if you run this yourself on a small model you actually use, does a trained skill outperform having no skill at all? To answer that, we’ll reproduce a small slice of the SearchQA experiment end-to-end in a single notebook and see whether the gains hold up in practice.
If you’d like to follow along or run the experiment yourself, feel free to reach out and I’ll share the notebook.
3.1 The experimental design: three arms, one model
The goal of the setup is to isolate the skill as the only variable. The target model, dataset, and evaluation procedure remain identical across all runs. The only thing that changes is the skill document injected into the prompt.
The three evaluation arms are:
baseline: The model receives no skill at all.
paper_ckpt: Uses a skill trained by the paper’s authors and evaluated without further optimization. It serves as a transfer test, measuring whether a skill optimized elsewhere remains effective when applied to the target model without additional training.
self_trained: Uses a skill produced by running the full SkillOpt optimization loop. This measures whether the training process itself can generate a useful skill under the available compute budget and experimental setup.
Each run is evaluated with two metrics:
hard: exact-match accuracy, the primary SearchQA metric used in the paper.soft: token-level F1, which gives partial credit when the answer contains the correct span but is not an exact match.
Reporting both metrics reveals when the model knows the answer but formats it poorly. A high soft score paired with a low hard score highlights exactly where a skill can help.
3.2 The setup: model, optimizer, and data
The experiment uses an asymmetric configuration that reflects a realistic deployment setup:
Target model:
gpt-5-nano: a small, inexpensive model that answers every question in all three evaluation arms.Optimizer model:
gpt-5: a stronger model that analyzes trajectories and proposes skill edits during training. It is used only in theself_trainedarm.
This follows the paper’s core design: a stronger optimizer trains a skill for a weaker target model. While the skill cannot add knowledge the target model does not possess, a capable optimizer can discover better procedures, instructions, and formatting rules for the target to follow.
The resulting splits contain:
Train: 400 examples used to generate rollout trajectories and optimize the skill.
Validation: 200 examples used by the held-out acceptance gate.
Test: 1,400 examples reserved for final evaluation and never seen during training.
Gold answers are used exclusively for scoring and validation. They are never included in the model’s input during inference.
3.3 Results
On the 100-item SearchQA evaluation slice, both skill-based arms beat the no-skill baseline.
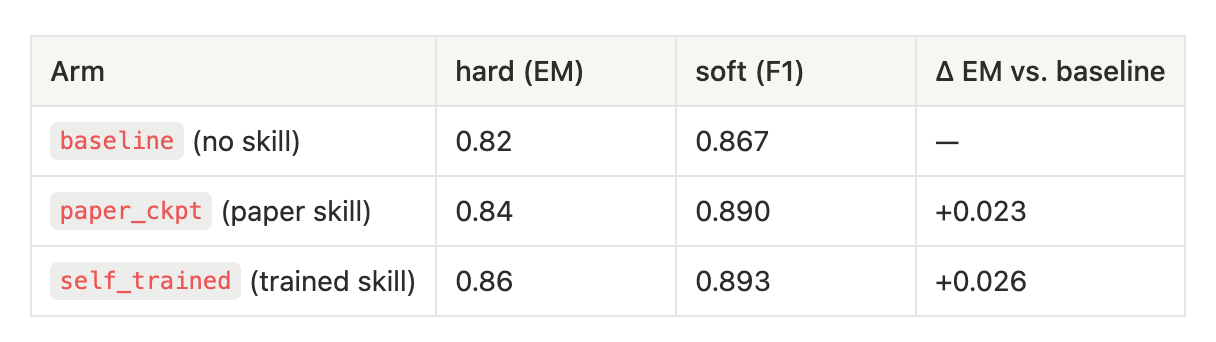
The main result is simple: holding the model, data, and evaluator fixed, adding a SkillOpt-trained skill improves performance over no skill.
Papers vs. trained model
The
paper_ckptarm is not a clean out-of-domain transfer test, since it was trained on a very similar SearchQA setup.The
self_trainedarm performs best. The gain overpaper_ckptis small, so this should not be read as a strong claim that the self-trained skill is better in general.
The hard/soft split is also informative.
The baseline already has a high soft F1 of 0.867, which means the model often retrieves or produces the right answer span. The lower hard EM shows that some errors are likely formatting or normalization errors rather than pure knowledge failures. Both skills raise hard EM and soft F1, suggesting that the improvement comes from cleaner extraction, stricter answer formatting, and better clue-to-answer matching.
The skill comparison supports this reading.
The paper skill is broad and reusable, covering answer normalization, evidence matching, clue interpretation, and common trivia traps. The self-trained skill keeps that base but adds stricter rules for this run, especially around <answer>...</answer> formatting, answer type, dates, quantities, cloze questions, articles, and numeric answers.
Note: This is not a full replication of the paper. It is a small reproduction on one benchmark slice and one small target model. Still, it answers the main question for this setup: a trained skill beats no skill, mostly by improving procedure rather than adding knowledge.
Key Takeaways
✓ A skill is trainable external state. SkillOpt updates the skill document while keeping the model weights and execution harness fixed. Every improvement can be traced to an explicit, inspectable edit.
✓ The loop behaves like an optimizer. Rollout, reflection, editing, and validation correspond to a forward pass, backward pass, bounded update, and validation check. An edit survives only if it improves held-out performance.
✓ The controls matter. The paper’s ablations show that the textual learning rate, rejected-edit buffer, slow update, and meta skill each contribute measurable gains.
✓ The results are strong but task-dependent. SkillOpt is best or tied-best across all 52 reported evaluation cells, with the largest gains on structured, procedural tasks and smaller improvements on open-ended QA.
✓ The ceiling remains the model. SkillOpt can improve how a model applies its capabilities, but not the capabilities themselves. Success depends on a capable optimizer, reliable evaluation, and a task that can be measured consistently.
References
[1] SkillOpt: Executive Strategy for Self-Evolving Agent Skills, Yang et al., arXiv:2605.23904, 2026. Link
[2] SkillOpt Project Page, Microsoft Research, 2026. Link
[3] microsoft/SkillOpt, GitHub repository, 2026. Link
[4] SearchQA dataset, Hugging Face. Link