
Scaling LangGraph Agents: Parallelization, Subgraphs, and Map-Reduce Trade-Offs
A Practical Guide to Choosing the Right Orchestration Strategy for Scalable LLM Workflows

This article is also available as a podcast! If you’re on the go or just want to absorb the content in audio format, you can listen to the full episode below 👇 The podcast is also available on Spotify and Apple Podcasts.

As agent systems grow from simple chains to complex multi-agent setups, the graphs meant to bring clarity end up creating confusion. What begins as a clean five-node workflow explodes into 30+ nodes, each relying on unclear state changes.
The key to scaling graph complexity is understanding when to parallelize independent work, when to encapsulate logic in subgraphs, and when to let the system dynamically spawn tasks based on runtime conditions.
Objective
This article focuses on solving three scalability problems: latency from sequential execution, complexity from oversized graphs, and rigidity from static workflows.
After reading this article, you will understand:
How to reduce latency through parallelization while managing concurrent state updates?
How to structure multi-agent architectures using subgraphs with isolated or shared state?
How to implement map-reduce patterns for variable workloads using the Send API?
This article is the fourth part of the LangGraph series on graph-based agent architectures. While earlier parts focused on individual graph components, Part 4 explores how to compose and orchestrate multiple agents efficiently.
Prerequisites: Basic knowledge of Python, LLMs, and prompt engineering is recommended. Readers should either be familiar with LangChain concepts (chains, models, prompts) or have read Part 1 of this series (or listen the podcast edition) to understand the foundations of LangGraph’s graph, node, and state model.
Tools & libraries: LangGraph, LangChain, LangSmith, OpenAI, arXiv API
You can find the code here on GitHub.
1. Understanding LangGraph’s Concurrency Models
1.1 When should parallelization be chosen over sequential execution?
What is parallelization in LangGraph?
Parallelization in LangGraph means executing multiple nodes simultaneously rather than one after another. Instead of waiting for one task to complete before starting the next, multiple tasks launch at the same time and run concurrently.
This is particularly valuable when making multiple independent API calls, database queries, or LLM requests that don’t depend on each other’s results.
In LangGraph, parallel execution is created by adding multiple edges from a single node to multiple destination nodes. The graph automatically detects this fan-out pattern and executes the destination nodes concurrently in what LangGraph calls a “superstep.”
Sequential vs. Parallel: A concrete example
Consider building a research assistant that answers questions by consulting both ArXiv (for academic papers) and Wikipedia (for general knowledge).
Sequential execution (one after another):
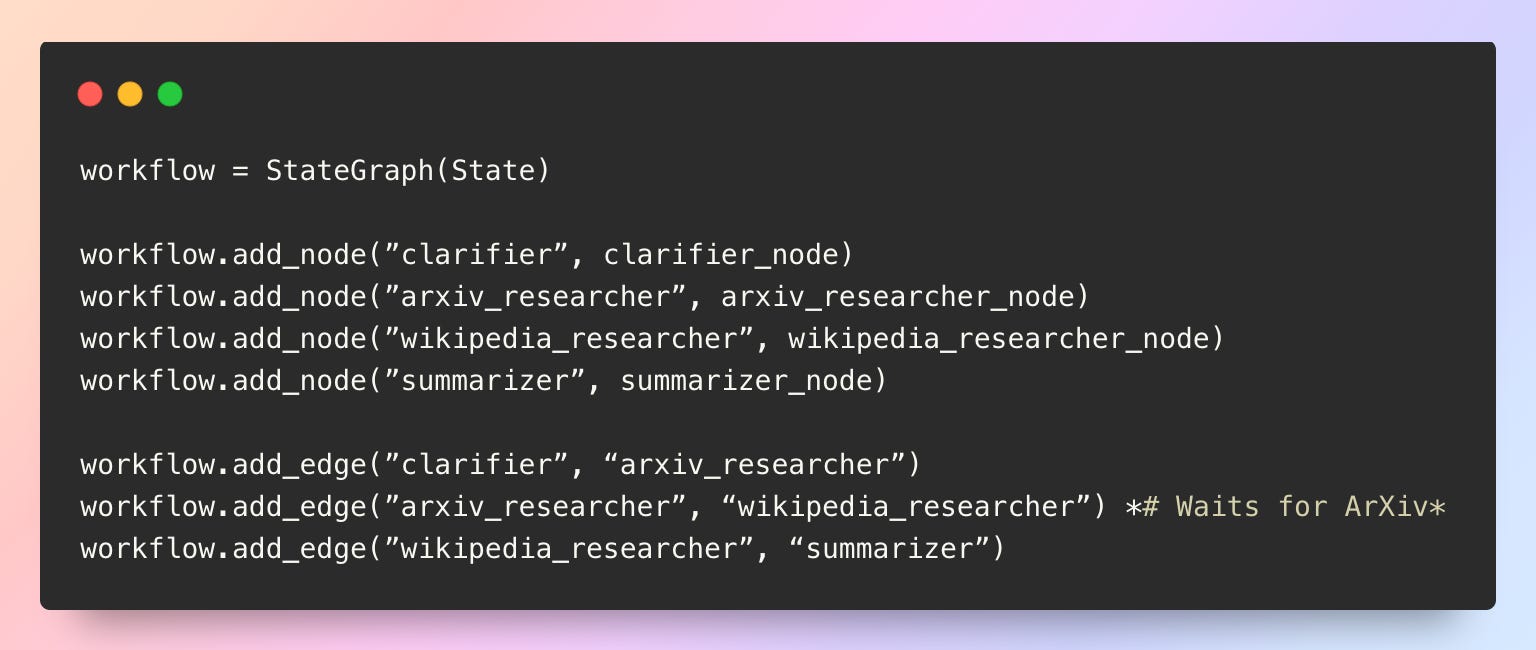
With sequential execution, if ArXiv takes 2 seconds and Wikipedia takes 2 seconds, the total wait time is 4 seconds.
Parallel execution (both at once):
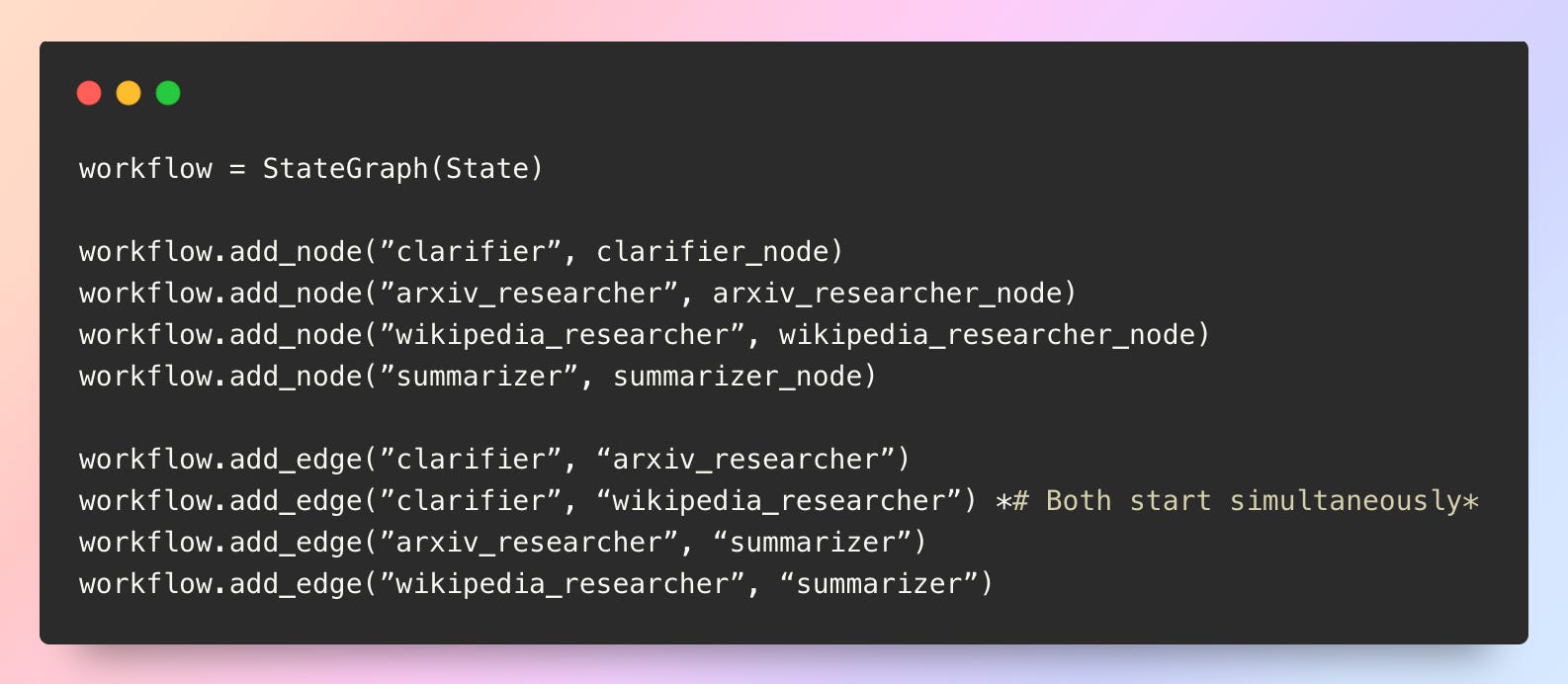
With parallel execution, both APIs are called simultaneously. The total wait time becomes only 2 seconds (the duration of the longest call), cutting execution time in half.
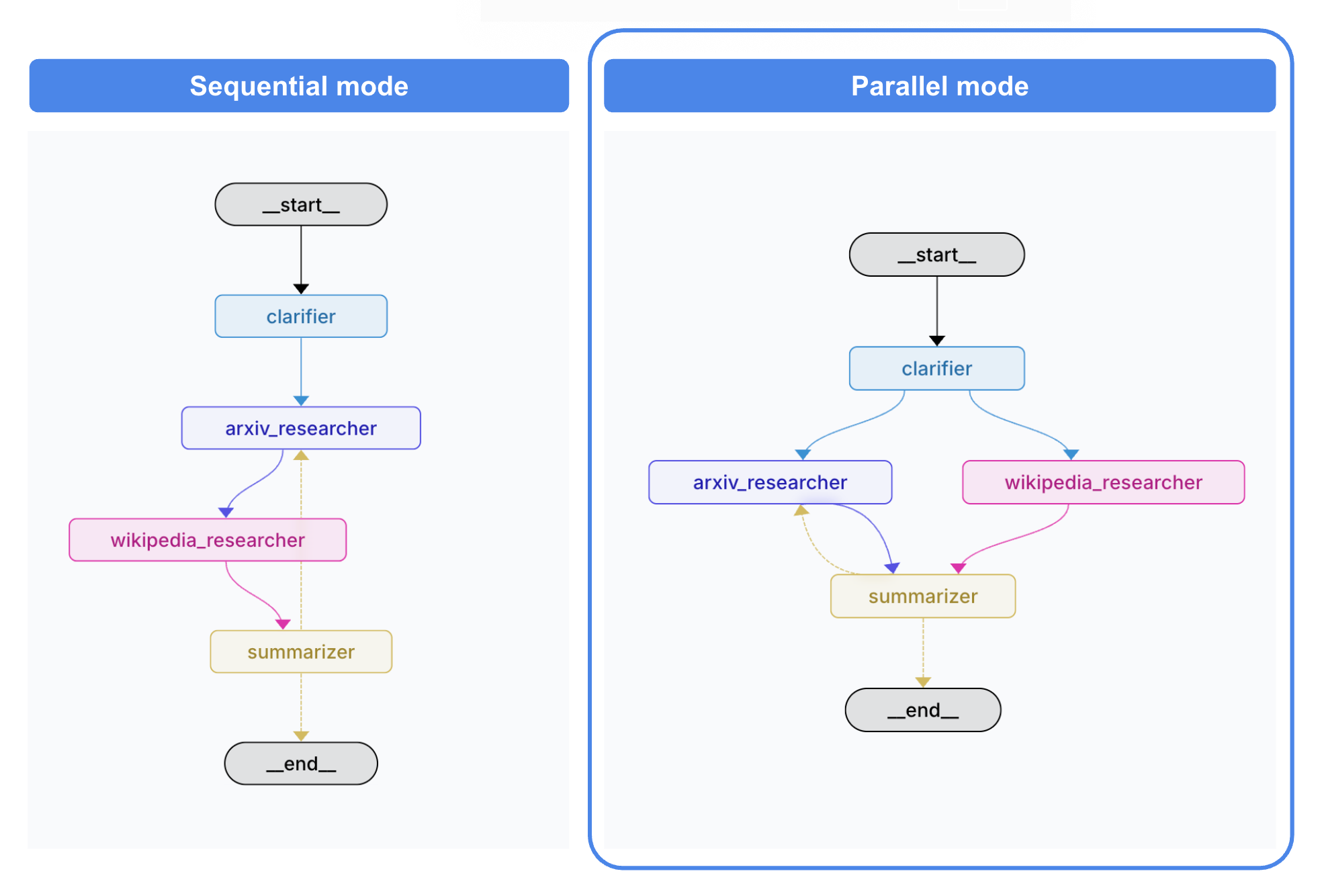
Comparisons:
In the research paper use case, running both tools sequentially took 61.46s, compared to just 0.45s when executed in parallel, a 137× speedup!
Key implementation considerations
The fundamental requirement for parallelization is independence. The ArXiv and Wikipedia calls work in parallel because neither needs the other’s output to proceed. When nodes truly run independently, parallelization delivers immediate performance gains.
However, state management requires careful attention. If both nodes update the same state key (like adding results to a “documents” list), reducers become essential to merge their updates properly. As discussed in the previous blog post on reducers (cf. Part 2 of the series), these functions define how concurrent updates combine.
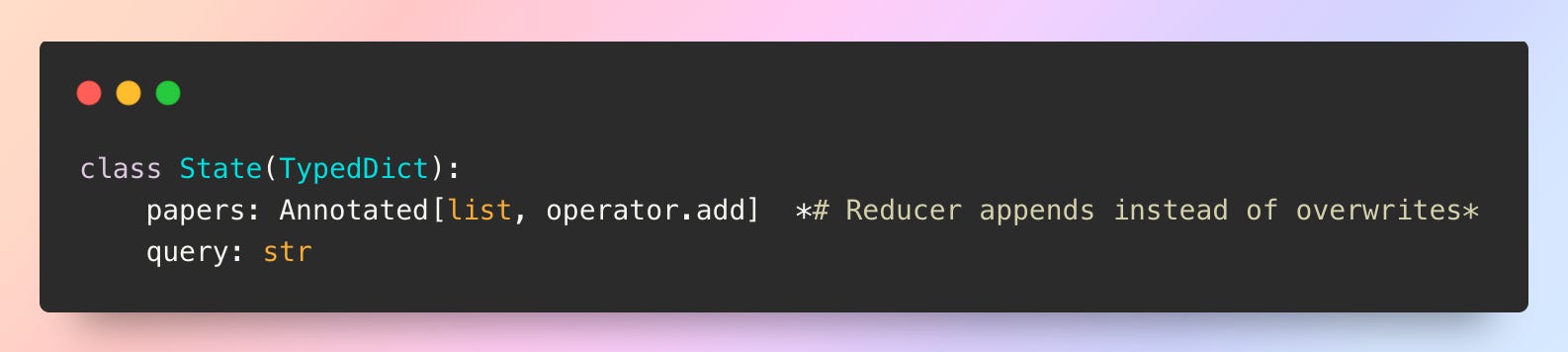
Understanding supersteps is crucial for managing parallel execution. A superstep is an execution unit in LangGraph that groups together nodes that can run concurrently. In our previous example, the graph detects multiple edges fanning out from a single node as ArXiv and Wikipedia starting simultaneously. It creates a superstep containing those parallel nodes. All nodes in a superstep execute at the same time and must all complete before the graph proceeds to the next step.
Error handling requires special consideration within supersteps. If one parallel node fails, the entire superstep fails atomically. This means if Wikipedia succeeds but ArXiv fails, neither result gets saved to state. This transactional behavior prevents inconsistent states but requires robust retry logic or fallback strategies in the node design. When using checkpointing, however, LangGraph saves results from successful nodes internally, so only failing branches need to retry when the graph resumes.
1.2 What are the performance trade-offs of concurrent node execution?
Speed gains vs. resource consumption
Parallel execution reduces latency but increases instantaneous resource usage. In the ArXiv and Wikipedia example, wait time drops from 4 seconds to 2 seconds, but two API calls now happen simultaneously instead of sequentially. This shift creates several practical implications.
Rate limits become a primary concern. If the Wikipedia API allows 60 requests per minute and five parallel searches run simultaneously, the quota gets consumed in 12 seconds instead of 1 minute. Monitoring and potentially throttling concurrent requests becomes necessary. LangGraph provides a
max_concurrencyconfiguration parameter to limit how many nodes can run at once, offering direct control over this trade-off.
Complexity vs. debuggability
Parallel execution trades simplicity for speed. Sequential execution offers a clear linear path to trace when problems occur. Parallel execution requires tracking multiple simultaneous paths, understanding how states merge, and diagnosing which branch caused failures. If a synthesis node fails, determining whether bad data came from ArXiv, Wikipedia, or both requires investigation.
Better logging and observability become essential. Execution traces show nodes completing in unpredictable order, making bug reproduction challenging. The trade-off is clear: parallelization delivers speed at the cost of operational complexity, making sense primarily when waiting on multiple slow external services that can run independently.
2. Subgraphs for Modular Agent Architectures
2.1 When to use isolated state vs. shared state between agents?
What are subgraphs in LangGraph?
Subgraphs are complete, self-contained graphs that can be embedded as nodes within a parent graph. They are reusable components or specialized agents that encapsulate their own logic and workflow. A subgraph is compiled independently and then added to a parent graph just like any other node, but internally it can have its own multi-step workflow, state schema, and execution logic. This architecture becomes particularly powerful for multi-agent systems. Instead of building one massive graph with dozens of nodes, the system can be decomposed into specialized agents (subgraphs), each responsible for a specific domain.
For example, a research assistant might have an orchestrator agent (parent graph) that delegates to specialized subgraphs: a literature review agent that searches and summarizes academic papers, a data extraction agent that pulls statistics and figures from documents, and a citation management agent that formats references. Each subgraph operates as an independent agent with its own internal workflow.
Shared state: the simple approach
The simplest subgraph pattern uses shared state keys between the parent and child graphs. According to the LangGraph subgraphs documentation, when a subgraph shares state keys with the parent graph, communication happens automatically through these shared channels. This is common in multi-agent systems where agents communicate over a shared “messages” key.
Consider a research system where an orchestrator agent (parent) delegates to specialized research agents (subgraphs):
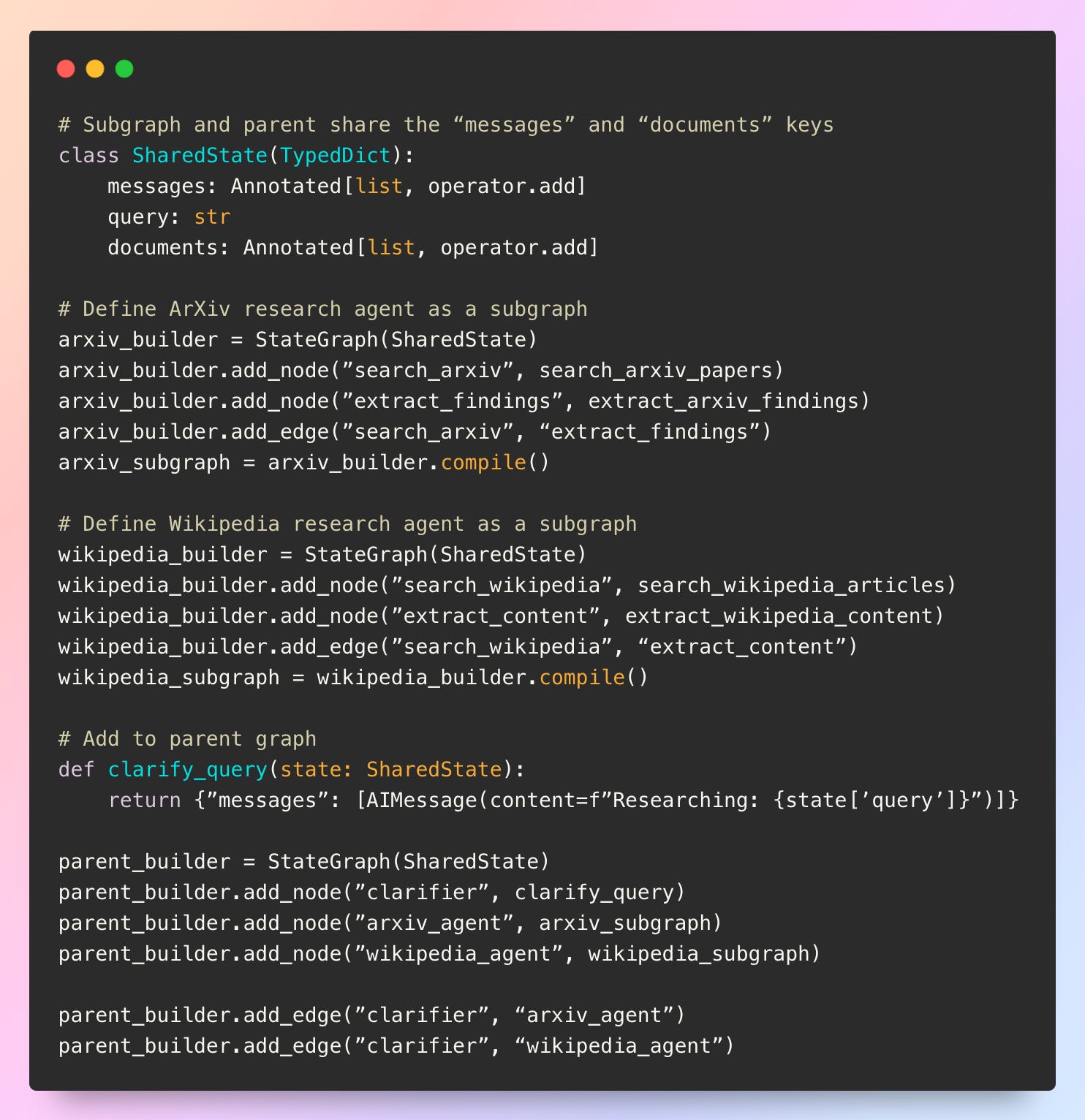
With shared state, the parent’s messages flow directly into the subgraph, the subgraph’s internal nodes can add more documents, and these updates flow back to the parent. This creates seamless communication but also means the subgraph can see and modify all parent state, which may not always be desired.
Isolated state: maintaining boundaries
Isolated state becomes necessary when agents need private information that shouldn’t leak to other parts of the system. With isolated state, the subgraph has its own schema completely independent from the parent. This requires explicit state transformation at the boundaries:
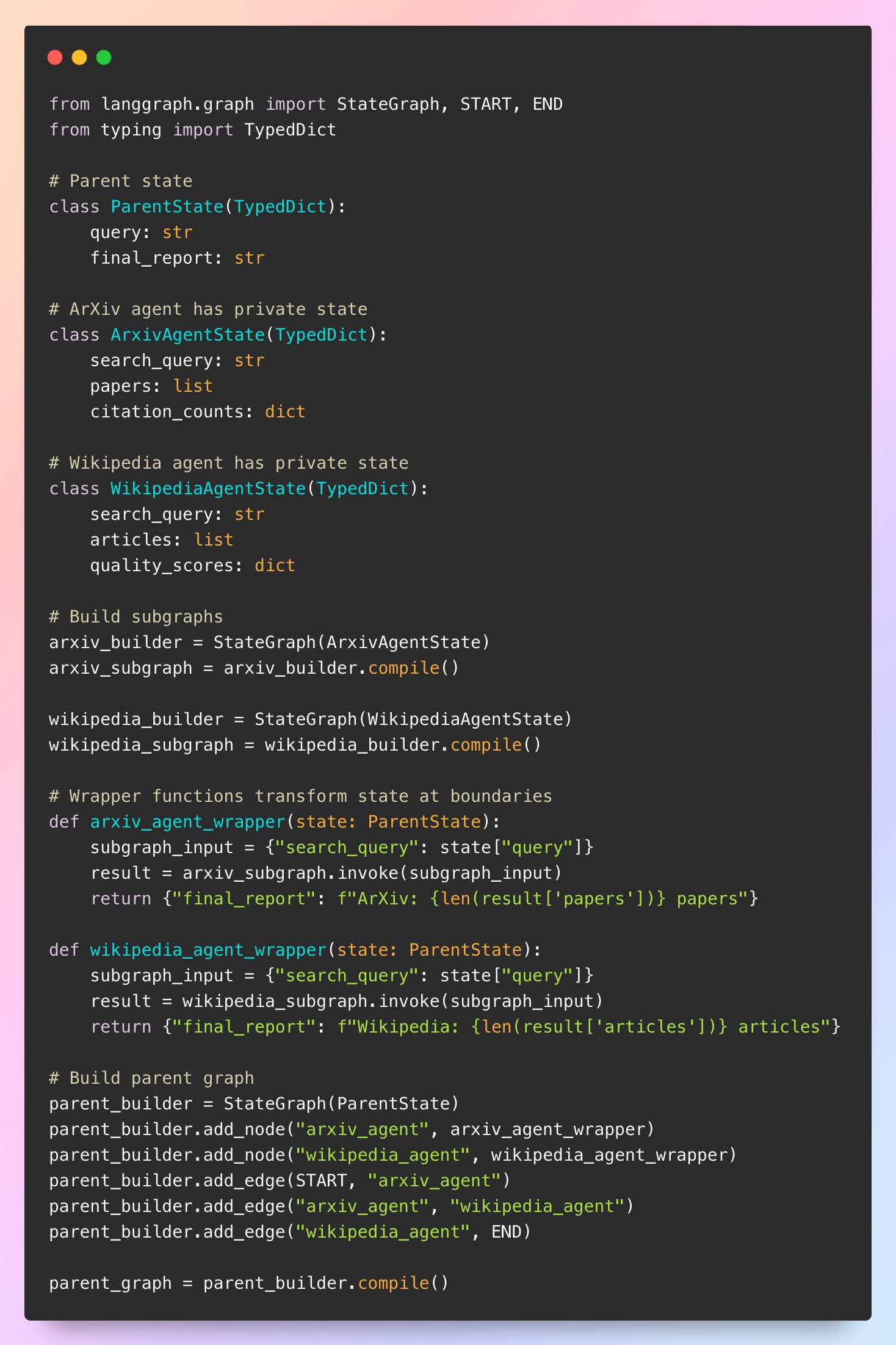
The trade-off is clear: shared state offers simplicity and automatic communication, while isolated state provides encapsulation and privacy at the cost of manual state transformation. The choice depends on whether agent boundaries need enforcement or whether seamless information flow is more valuable.
2.2 How to maintain separate memory for each agent in a multi-agent system?
Independent checkpointing for agent memory
Each subgraph can maintain its own memory by compiling it with a dedicated checkpointer. This is particularly useful in multi-agent systems where each agent needs to track its own internal history independently.
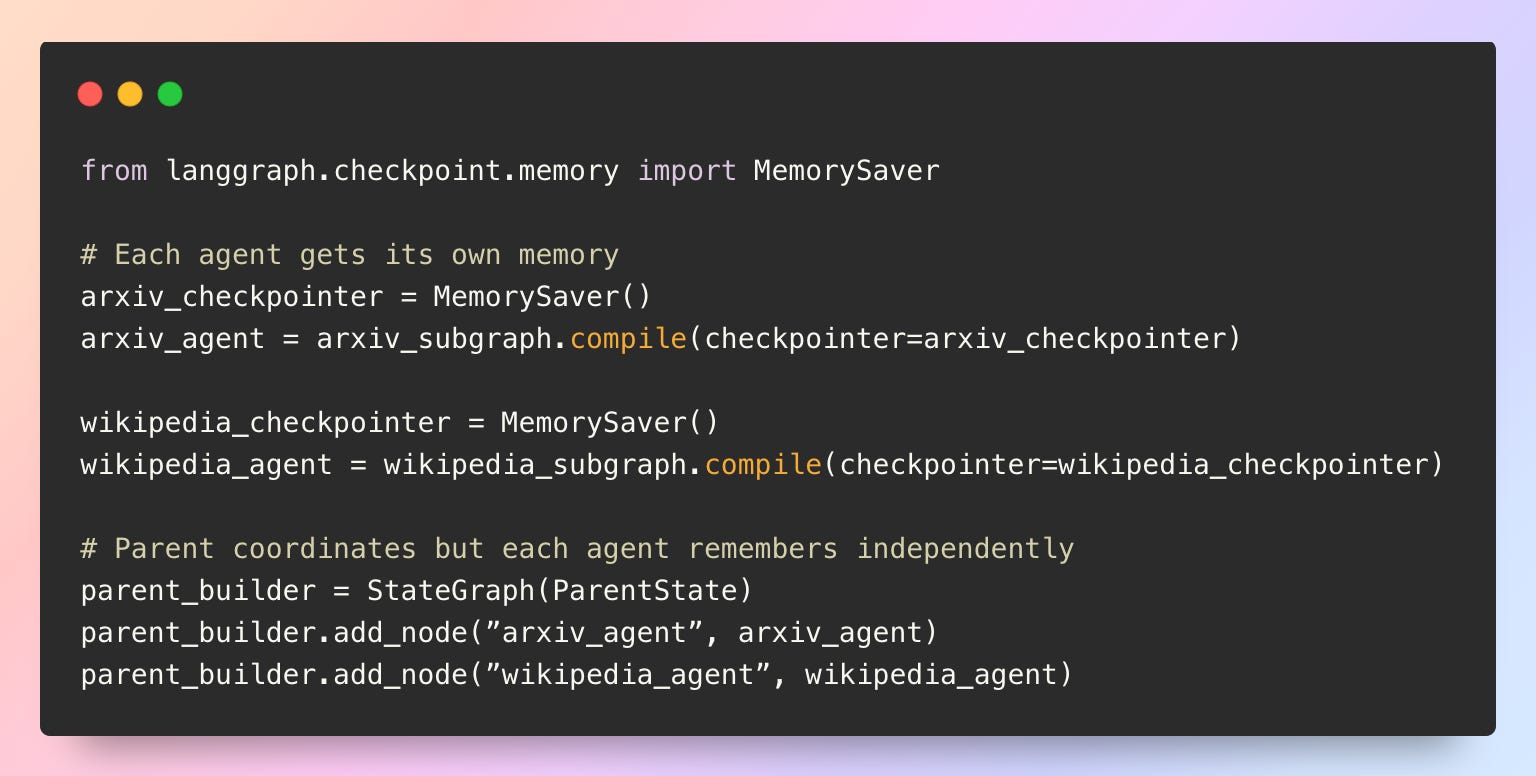
This architecture enables agents to build up expertise and context over time as each agent maintains focused, relevant memory for its domain.
Memory visibility and debugging
The documentation notes that subgraph state can be viewed using graph.get_state(config, subgraphs=True), but with an important caveat: subgraph state is only accessible when the subgraph is interrupted. Once execution resumes, that checkpoint moves into the past and is no longer directly accessible.
This has practical implications for debugging and monitoring. To understand what happened inside a subgraph, interruption points need strategic placement, or the subgraph needs to explicitly surface key information back to the parent state. For example, a literature review agent might maintain detailed paper evaluations in its private state but surface only the final summary to the parent.
3. Map-Reduce with the Send API
3.1 When should dynamic branching be used vs. static parallelization?
What is map-reduce in LangGraph?
Map-reduce is a pattern for distributing work across multiple parallel tasks and then aggregating their results.
The “map” phase splits work into independent units that process in parallel
The “reduce” phase combines their outputs.
In LangGraph, map-reduce is implemented using the Send API, which enables dynamic task creation at runtime where the number and configuration of parallel tasks are determined by the graph’s state rather than fixed at design time.
Consider a research assistant with a query clarifier that interprets ambiguous research questions in multiple ways. The number of interpretations isn’t known until the clarification completes, and each interpretation needs separate processing.
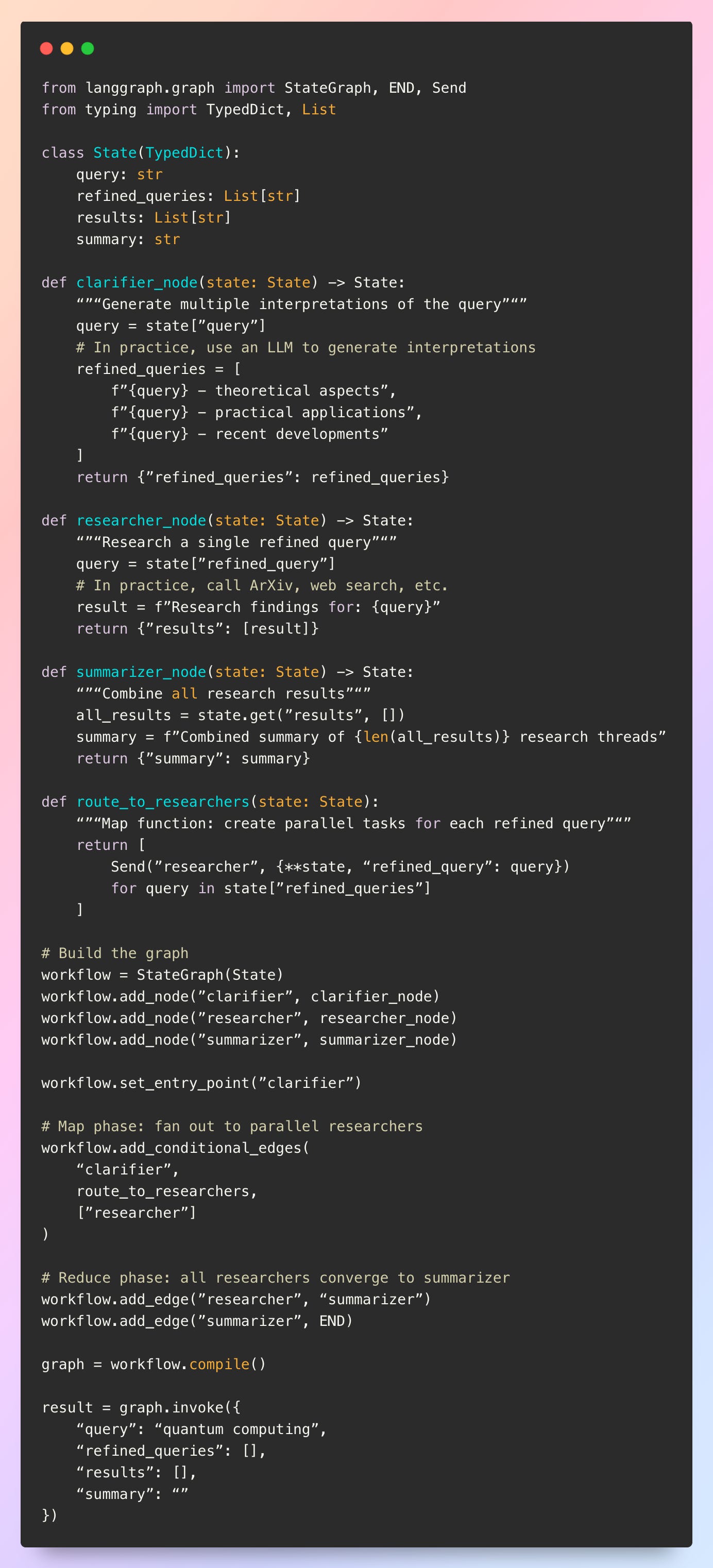
The route_to_reaserchers function returns a list of Send objects, each specifying which node to invoke and with what state. LangGraph executes all these search tasks in parallel within a single superstep, then proceeds to synthesis once all complete.
The trade-off: flexibility vs. simplicity
Map-reduce provides flexibility for variable workloads but introduces complexity. The graph structure isn’t fully visible at design time since the number of parallel tasks depends on runtime state. A query might generate 2 interpretations or 10, creating different execution patterns each run. This makes visualization and debugging more challenging.
Static parallelization offers simplicity and predictability but lacks adaptability. The choice depends on whether the parallel structure is truly fixed. For research tasks where interpretation counts vary (sometimes needing 2 searches, sometimes 8), map-reduce is essential. For fixed API queries with consistent structure (always ArXiv + PubMed + Semantic Scholar), static parallelization is cleaner and more maintainable.
3.2 What happens when parallel branches have different execution lengths?
The challenge of uneven task durations
In static parallelization with fixed APIs, branches typically complete around the same time since they perform similar operations. With map-reduce, different tasks may require drastically different processing times. A research assistant searching multiple query interpretations might get instant results for one interpretation (cached or simple query) but wait 20 seconds for another (complex query requiring extensive processing).
The problem emerges when these tasks of different lengths need to converge. Consider a graph that searches multiple interpretations in parallel, then synthesizes findings. If the synthesis node starts as soon as the first search finishes, it works with incomplete data. The graph needs a way to ensure all parallel work completes before proceeding.
The defer parameter for synchronization
In LangGraph, when multiple parallel branches converge to the same node, the system automatically waits for all branches to complete before proceeding Langchain. This built-in synchronization is fundamental to how LangGraph’s superstep execution model works.
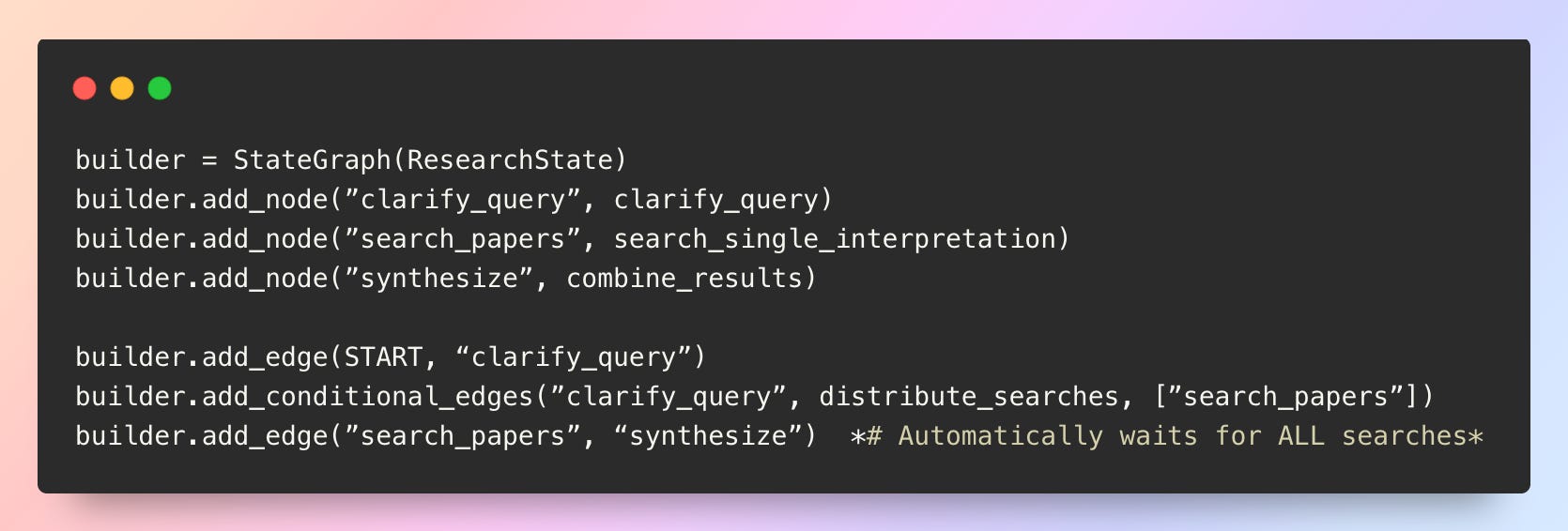
The synthesize node automatically waits for every parallel search_papers instance to complete—no special configuration needed. However, defer=True is useful when branches have different lengths and you want to delay a node’s execution until all other pending tasks are completed Langchain. It’s passed as a parameter to add_node():
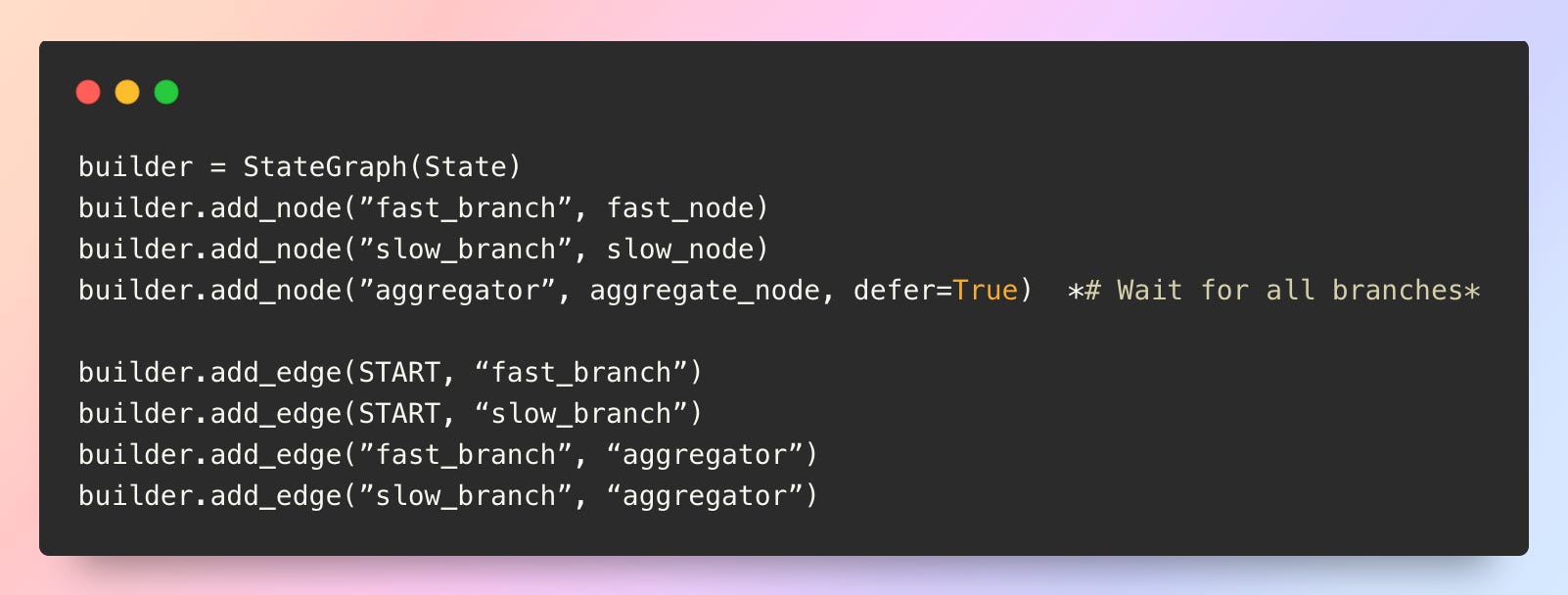
Without defer=True, when branches execute in the same superstep, the downstream node naturally waits for all parallel branches to finish Langchain. With defer=True, the node explicitly waits until all pending tasks across different branch lengths are completed—ensuring complete data collection even when branches have asymmetric execution paths.
Key Takeaways
✓ Parallelization delivers dramatic speedups when tasks are independent: By executing multiple nodes simultaneously rather than sequentially, parallel execution can reduce latency. However, this requires careful state management with reducers to merge concurrent updates and avoid data loss.
✓ Subgraphs enable modular multi-agent architectures with isolated or shared state: Use shared state for seamless communication between agents when information needs to flow freely, or isolated state with explicit transformation functions when agents need privacy and clear boundaries between their internal workings.
✓ Map-reduce with the Send API adapts to variable workloads at runtime: Unlike static parallelization with fixed branches, map-reduce dynamically creates parallel tasks based on runtime conditions. This is essential when the number of tasks varies (e.g., processing 2 vs. 10 query interpretations) but adds complexity to debugging and visualization.
References
[1] LangGraph Documentation - Parallelization and Concurrency, LangChain AI, 2024
[2] LangGraph Documentation - Subgraphs, LangChain AI, 2024
[3] LangGraph Documentation - Map-Reduce with Send API, LangChain AI, 2024
[4] LangGraph Documentation - Node Execution and Supersteps, LangChain AI, 2024
Brilliant. This article really hits the nail on the head. Those exploding 30+ node graphs are a nightmare. Your breakdown of parallelization and subgraphs feels like the clarity we need, even if it's always tricker in practice.